![ruCLIP Large [vit-large-patch14-336] exclusive-image](https://cdn.cloud.ru/backend/images/rugpt3family/ruclip_large_exclusive.png)
ruCLIP Large [vit-large-patch14-336] exclusive
Russian Contrastive Language–Image Pre-training. Модель-ранжировщик текстов и изображений, 430 млн параметров.
ruCLIP - это мультимодальная модель для ранжирования изображений и подписей к ним, а также получения семантической близости изображений и текстов. Архитектура впервые представлена OpenAI.
Apache 2.0
1.5 GB
0.1
ruCLIP (Russian Contrastive Language – Image Pre-training) обучена для русского языка на открытых данных, собранных из Рунета.
240 миллионов уникальных пар картинка-текст в обучающей выборке.
Информация об использовании модели:
Эксклюзивная версия модели ruCLIP, доступная только на платформе Cloud.ru. Модель отличает сочетание меньшего размера патча - 14 и большего размера входных изображений - 336. Данное сочетание привело к наиболее высоким качественным результатам оценки модели - на 12 из 18 датасетах (zero-shot задача), на 5 из 16 датасетах (few-shot задача).
ruCLIP — это модель, состоящая из двух частей (или нейронных сетей):
- Image Encoder — часть для кодирования изображений и перевода их в общее векторное пространство. В качестве архитектуры в оригинальной работе берутся ResNet разных размеров и Visual Transformer — тоже разных размеров. В ruCLIP Large в качестве image encoder используется ViT-L/14.
- Text Encoder — часть для кодирования текстов и перевода их в общее векторное пространство. В качестве архитектуры используется текстовый Transformer.
Similarity

[{"собачка": 0.9913390278816223}, {"кошка": 0.0070372591726481915}, {"мышка": 5.551231879508123e-05}, {"машина": 0.000418326846556738}, {"стол": 0.0001436278544133529}, {"дом": 0.00010760522854980081}, {"жидкость": 0.0008986211032606661}]
KFServing
Класс KFServingRuClipModel представлен ниже.
Вы можете подавать на вход модели:
- ссылки на изображения
- картинки в формате base64
На выходе модель покажет близость между текстами и картинками. Чем ближе значение к 1, тем ближе семантическое сходство картинки и текста.
import os
import json
from collections import OrderedDict
from typing import Dict
import kfserving
import requests
import torch
import numpy as np
import io
from io import BytesIO
import base64
from PIL import Image
import re
from ruclip import CLIP, RuCLIPProcessor
def open_images_base64(img_strs):
return [Image.open(BytesIO(base64.b64decode(img_str))) for img_str in img_strs]
def open_image_link(links):
imgs = []
for img_link in links:
response = requests.get(img_link)
imgs.append(Image.open(BytesIO(response.content)))
return imgs
def create_image(sim_plt):
my_stringIObytes = io.BytesIO()
sim_plt.savefig(my_stringIObytes, format="jpg")
my_stringIObytes.seek(0)
my_base64 = base64.b64encode(my_stringIObytes.read())
return my_base64
class KFServingRuClipModel(kfserving.KFModel):
def __init__(self, title: str, model_path="./ruclip-vit-large-patch14-336"):
super().__init__(name)
self.name = name
self.ready = False
self.model_path = model_path
def load(self):
self.device = "cuda"
self.clip = CLIP.from_pretrained(self.model_path).eval().to(self.device)
self.clip_processor = RuCLIPProcessor.from_pretrained(self.model_path)
self.ready = True
def get_text_latents(self, texts):
with torch.no_grad():
inputs = self.clip_processor(text=texts, images=None)
text_latents = self.clip.encode_text(
input_ids=inputs["input_ids"].to(self.device),
)
text_latents = text_latents / text_latents.norm(dim=-1, keepdim=True)
return text_latents
def get_logits(self, text_latents, pil_images):
with torch.no_grad():
inputs = self.clip_processor(text=None, images=pil_images)
image_latents = self.clip.encode_image(
pixel_values=inputs["pixel_values"].to(self.device)
)
image_latents = image_latents / image_latents.norm(dim=-1, keepdim=True)
logits_per_text = torch.matmul(text_latents, image_latents.t())
logits_per_image = logits_per_text.t()
return logits_per_text, logits_per_image
def get_similarity_scores(self, texts, images):
"""
Find the most similar image to text.
`texts`: array of texts or one text ["some_desc"]
`images`: array of images.
"""
text_latents = self.get_text_latents(texts)
results = []
for pil_image in images:
_, logits_per_image = self.get_logits(text_latents, [pil_image])
probs_raw = (logits_per_image * self.clip.logit_scale.exp().detach()).softmax(dim=-1)[0]
label_id = probs_raw.argmax().item()
confidence = probs_raw.max().item()
probs = []
for i in range(len(texts)):
probs.append({texts[i]: probs_raw[i].item()})
buffered = BytesIO()
pil_image.save(buffered, format="JPEG")
img = base64.b64encode(buffered.getvalue()).decode("utf-8")
results.append({"image": img, "text": texts[label_id], "confidence" : confidence, "all_res": probs})
return results
def predict(self, request: Dict) -> Dict:
texts = request["instances"][0]["texts"]
img_strs = request["instances"][0].get("images", None)
if img_strs is not None:
images = open_images_base64(img_strs)
images_links = request["instances"][0].get("image_links", None)
if images_links is not None:
images = open_image_link(images_links)
error_msg = None
predictions = []
try:
predictions = self.get_similarity_scores(texts, images)
except Exception as ex:
print(ex)
error_msg = ex
if error_msg is not None:
return {"predictions": predictions, "error_message": str(error_msg)}
else:
return {"predictions": predictions}
Функция predict возвращает массив со словарями для каждой картинки вида:
predictions: [
{
"image": "base64 image",
"text": "наиболее подходящий текст для картинки" ,
"confidence": "мера близости для лучшей картинки",
"all_res": [{"менее вероятный текст": 0.31}, {"другой текст": 0.33},} ...]
}
]
Пример работы с моделью
!pip install -r requirements.txt
from kfserving_ru_CLIP import KFServingRuClipModel
model = KFServingRuClipModel("kfserving-clip")
model.load()
# zero-shot and links
url_cat = "https://cs11.livemaster.ru/storage/topic/NxN/2c/9b/9cf0a41d13ecb11439e6145dff576315df83op.jpg?h=3KvOPndE06tlraLLSmkHPQ"
url_cat2 = "https://pbs.twimg.com/profile_images/560798448962633728/rDEdUfV_.jpeg"
url_dog = "https://ichef.bbci.co.uk/news/640/cpsprodpb/475B/production/_98776281_gettyimages-521697453.jpg"
result = model.predict({"instances": [{
"texts": ["собачка", "кошка", "мышка", "машина", "стол", "дом", "жидкость"],
"image_links": [url_dog, url_cat, url_cat2]
}]
})
"Res: ", result
`{"predictions": "[{"image": b"/9j/4AAQSkZJRgABAQAAAQABAAD/2wBDAAgGBgcGBQ...", "text": "собачка", "confidence": 0.9913390278816223,"all_res": [{"собачка": 0.9913390278816223}, {"кошка": 0.0070372591726481915}, {"мышка": 5.551231879508123e-05}, {"машина": 0.000418326846556738}, {"стол": 0.0001436278544133529}, {"дом": 0.00010760522854980081}, {"жидкость": 0.0008986211032606661}]}, ... ]", "error_message": None}`
Оценки модели на популярных датасетах
Косинусная близость между текстами и картинками для модели ruCLIP

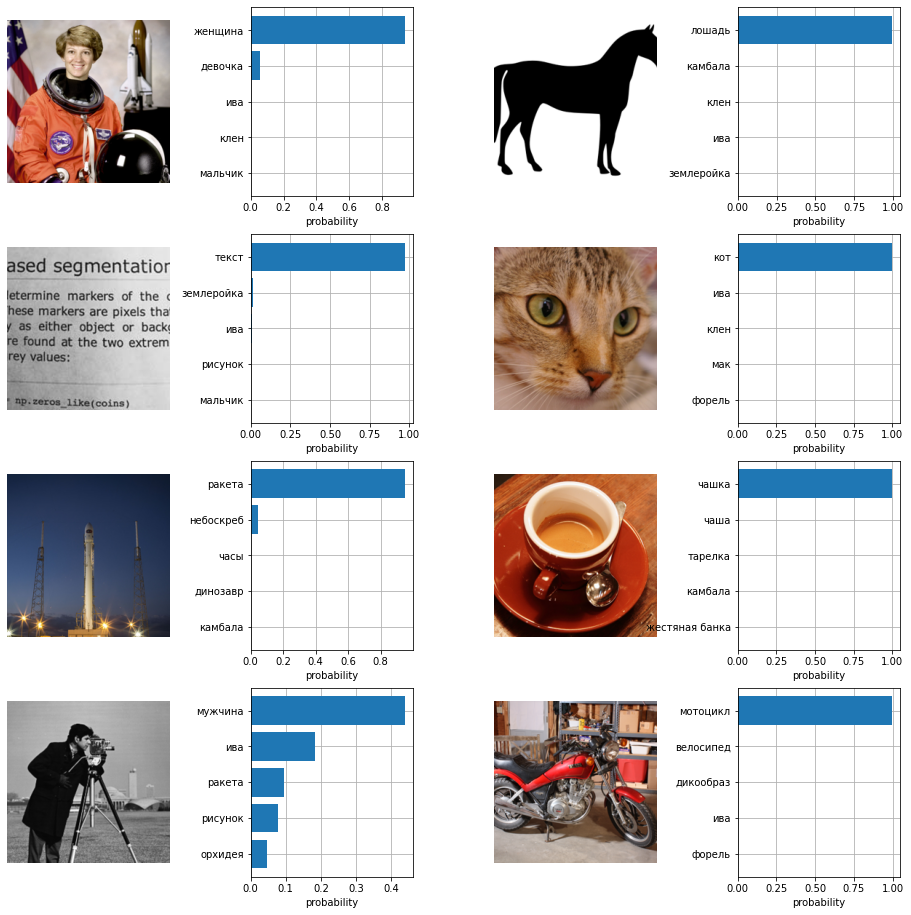
Предсказания топ 5 классов для изображений с помощью ruCLIP
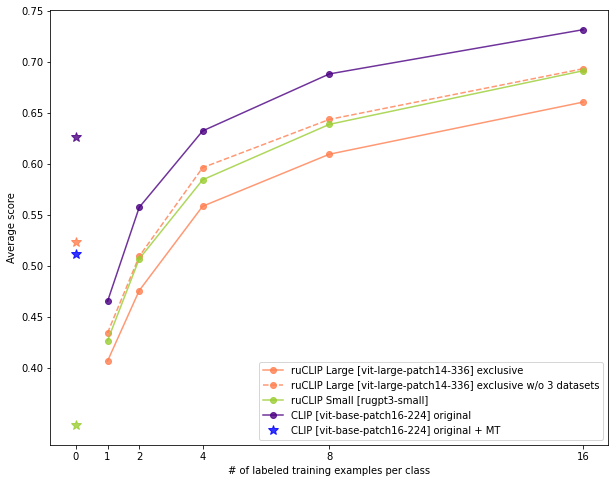
Сравнение моделей на задаче zero-shot классификации для разных датасетов. Жирным выделена лучшая метрика для каждого из датасетов без учета оригинального CLIP без переводчика.
| ruCLIP Small [rugpt3-small] | ruCLIP Large [vit-large-patch14-336] exclusive | CLIP [vit-base-patch16-224] original + MT | CLIP [vit-base-patch16-224] original | |
|---|---|---|---|---|
| Food101 | 0.137 | 0.711 | 0.663 | 0.882 |
| CIFAR10 | 0.808 | 0.905 | 0.859 | 0.892 |
| CIFAR100 | 0.439 | 0.591 | 0.602 | 0.647 |
| Birdsnap | 0.035 | 0.213 | 0.126 | 0.395 |
| SUN397 | 0.257 | 0.523 | 0.447 | 0.631 |
| Stanford Cars | 0.022 | 0.658 | 0.567 | 0.637 |
| DTD | 0.168 | 0.407 | 0.242 | 0.432 |
| MNIST | 0.137 | 0.241 | 0.558 | 0.558 |
| STL10 | 0.909 | 0.956 | 0.966 | 0.970 |
| PCam | 0.484 | 0.553 | 0.602 | 0.572 |
| CLEVR | 0.104 | 0.142 | 0.240 | 0.240 |
| Rendered SST2 | 0.482 | 0.538 | 0.483 | 0.483 |
| FGVC Aircraft | 0.019 | 0.075 | 0.219 | 0.244 |
| Oxford Pets | 0.462 | 0.545 | 0.506 | 0.873 |
| Caltech101 | 0.589 | 0.835 | 0.791 | 0.882 |
| HatefulMemes | 0.527 | 0.518 | 0.579 | 0.589 |
| ImageNet | 0.537 | 0.488 | 0.391 | 0.638 |
| Flowers102 | 0.063 | 0.516 | 0.356 | 0.696 |
Звездочками показана средняя zero-shot оценка моделей на 16 датасетах. Также, как и в статье, на признаках, которые достает CLIP для изображений были обучены логистические регрессии с использованием 1-2-4-8-16 изображений для каждого класса. Поскольку признаки, которые извлекаются у openai и openai_mt одинаковые — для openai_mt нет отдельного графика few-shot классификации. Также мы посчитали усредненный few-shot график для модели ruCLIP Large exclusive без учета трех датасетов - PCam, Oxford Pets и FGVC Aircraft, на которых модель проигрывает достаточно сильно и можно видеть (пунктирная линия), что среднее качество немного превосходит ruCLIP Small.
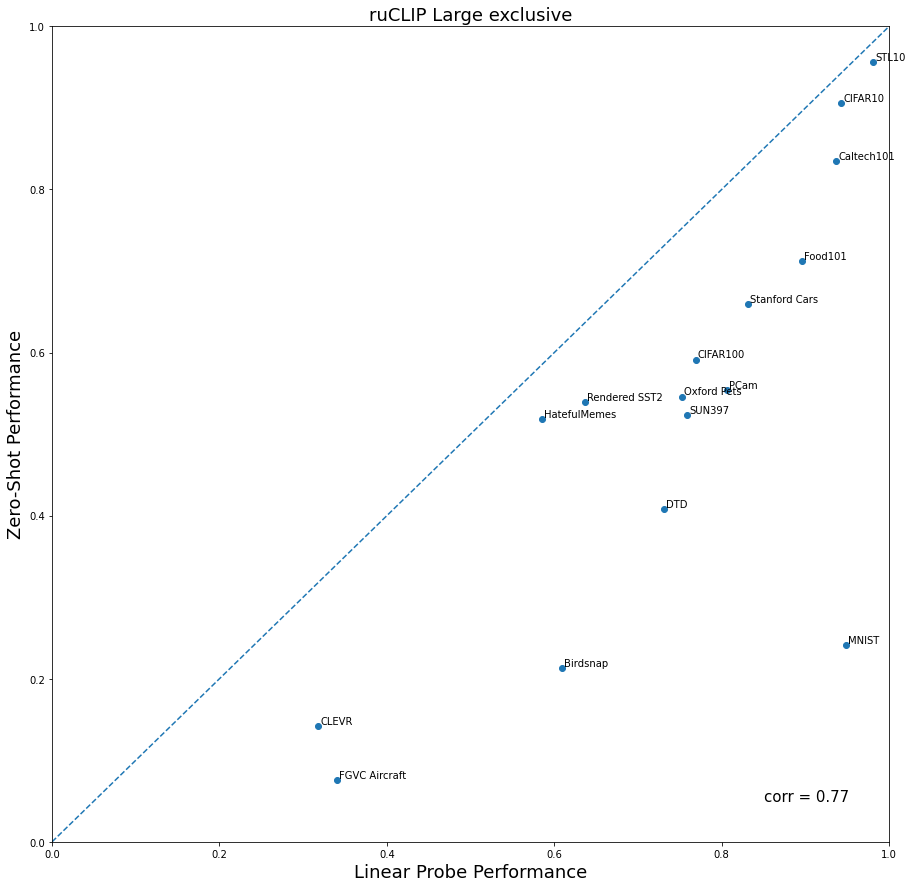
То же самое, но отдельно по каждому датасету.

Сравнение linear-prob метрики для трех моделей на разных датасетах.
| ruCLIP Small [rugpt3-small] | ruCLIP Large [vit-large-patch14-336] exclusive | CLIP [vit-base-patch16-224] original | |
|---|---|---|---|
| Food101 | 0.873 | 0.896 | 0.900 |
| CIFAR10 | 0.948 | 0.943 | 0.953 |
| CIFAR100 | 0.794 | 0.769 | 0.807 |
| Birdsnap | 0.584 | 0.609 | 0.664 |
| SUN397 | 0.752 | 0.758 | 0.776 |
| Stanford Cars | 0.806 | 0.831 | 0.865 |
| DTD | 0.737 | 0.730 | 0.769 |
| MNIST | 0.985 | 0.949 | 0.988 |
| STL10 | 0.977 | 0.981 | 0.982 |
| PCam | 0.833 | 0.806 | 0.830 |
| CLEVR | 0.524 | 0.318 | 0.604 |
| Rendered SST2 | 0.568 | 0.637 | 0.605 |
| FGVC Aircraft | 0.499 | 0.340 | 0.604 |
| Oxford Pets | 0.894 | 0.753 | 0.931 |
| Caltech101 | 0.936 | 0.936 | 0.955 |
| HatefulMemes | 0.637 | 0.585 | 0.645 |
Здесь указаны графики корреляции zero-shot и linear-prob результатов для разных моделей.
ruCLIP Large [vit-large-patch16-336] exclusive
ruCLIP Small [rugpt3-small]

CLIP [vit-base-patch16-224] original + MT

CLIP [vit-base-patch16-224] original
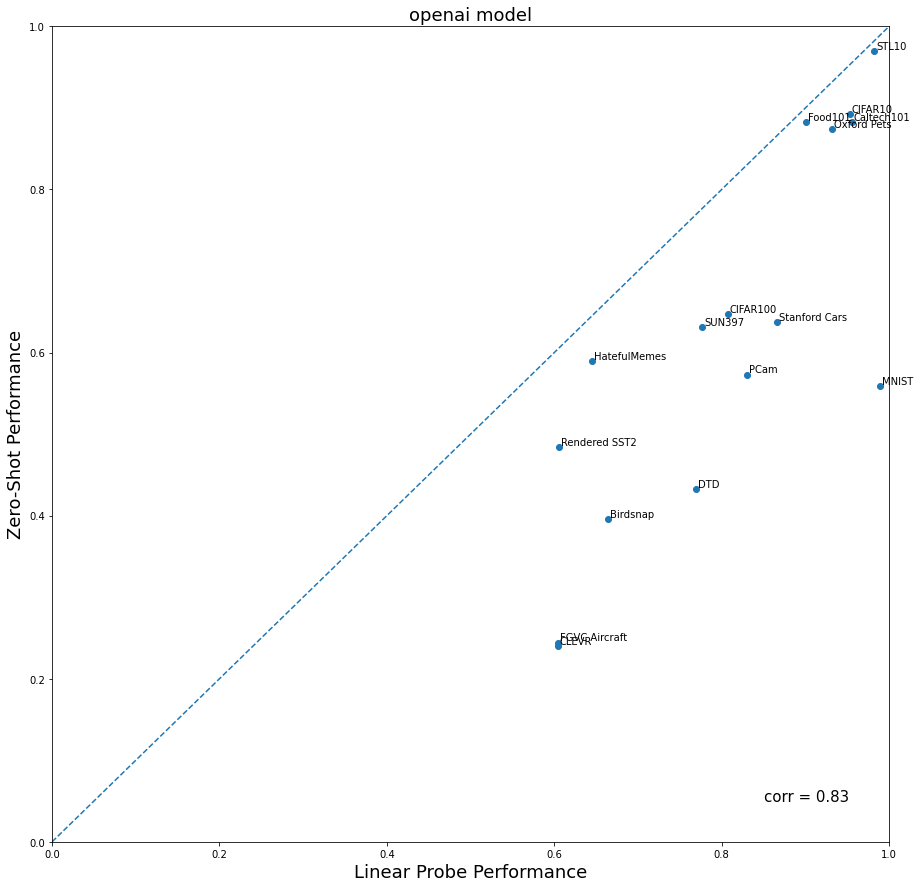
Сравнение разных моделей на ImageNet датасетах.
| resnet101 | CLIP [vit-base-patch16-224] original | CLIP [vit-base-patch16-224] original + MT | ruCLIP Large [vit-large-patch14-336] exclusive | ruCLIP Small [rugpt3-small] | |
|---|---|---|---|---|---|
| ImageNet | 0.738 | 0.638 | 0.391 | 0.488 | 0.537 |
| ImageNetV2 | 0.618 | 0.581 | 0.353 | 0.430 | 0.458 |
| ImageNet-R | 0.271 | 0.489 | 0.352 | 0.525 | 0.240 |
| ImageNet-A | 0.021 | 0.265 | 0.156 | 0.229 | 0.080 |
| ImageNet-Sketch | 0.264 | 0.448 | 0.291 | 0.419 | 0.250 |
Zero-shot классификация для разных датасетов на моделях ruCLIP.
| ruCLIP Large [vit-large-patch14-336] exclusive | ruCLIP Large [vit-large-patch14-224] | ruCLIP Base [vit-base-patch32-384] | ruCLIP Base [vit-base-patch16-384] exclusive | |
|---|---|---|---|---|
| Food101, acc | 0.712 💥 | 0.597 | 0.642 | 0.689 |
| CIFAR10, acc | 0.906 💥 | 0.878 | 0.862 | 0.845 |
| CIFAR100, acc | 0.591 💥 | 0.511 | 0.529 | 0.569 |
| Birdsnap, acc | 0.213 💥 | 0.172 | 0.161 | 0.195 |
| SUN397, acc | 0.523 💥 | 0.484 | 0.510 | 0.521 |
| Stanford Cars, acc | 0.659 💥 | 0.559 | 0.572 | 0.626 |
| DTD, acc | 0.408 | 0.370 | 0.390 | 0.421 💥 |
| MNIST, acc | 0.242 | 0.337 | 0.404 | 0.478 💥 |
| STL10, acc | 0.956 | 0.934 | 0.946 | 0.964 💥 |
| PCam, acc | 0.554 💥 | 0.520 | 0.506 | 0.501 |
| CLEVR, acc | 0.142 | 0.152 | 0.188 💥 | 0.132 |
| Rendered SST2, acc | 0.539 💥 | 0.529 | 0.508 | 0.525 |
| ImageNet, acc | 0.488 💥 | 0.426 | 0.451 | 0.482 |
| FGVC Aircraft, mean-per-class | 0.075 💥 | 0.046 | 0.053 | 0.046 |
| Oxford Pets, mean-per-class | 0.546 | 0.604 | 0.587 | 0.635 💥 |
| Caltech101, mean-per-class | 0.835 💥 | 0.777 | 0.834 | 0.835 💥 |
| Flowers102, mean-per-class | 0.517 💥 | 0.455 | 0.449 | 0.452 |
| Hateful Memes, roc-auc | 0.519 | 0.530 | 0.537 | 0.543💥 |
Few-shot классификация для разных датасетов на моделях ruCLIP.
| ruCLIP Large [vit-large-patch14-336] exclusive | ruCLIP Large [vit-large-patch14-224] | ruCLIP Base [vit-base-patch32-384] | ruCLIP Base [vit-base-patch16-384] exclusive | |
|---|---|---|---|---|
| Food101 | 0.896 💥 | 0.840 | 0.851 | 0.890 |
| CIFAR10 | 0.943 💥 | 0.927 | 0.934 | 0.942 |
| CIFAR100 | 0.770 | 0.734 | 0.745 | 0.773 💥 |
| Birdsnap | 0.609 | 0.567 | 0.434 | 0.612 💥 |
| SUN397 | 0.759 💥 | 0.731 | 0.721 | 0.758 |
| Stanford Cars | 0.831 | 0.797 | 0.766 | 0.840 💥 |
| DTD | 0.731 | 0.711 | 0.703 | 0.749 💥 |
| MNIST | 0.949 | 0.949 | 0.965 | 0.971 💥 |
| STL10 | 0.981 💥 | 0.973 | 0.968 | 0.974 |
| PCam | 0.807 | 0.791 | 0.835 | 0.846 💥 |
| CLEVR | 0.318 | 0.358 | 0.308 | 0.378 💥 |
| Rendered SST2 | 0.637 | 0.651 | 0.651 | 0.661 💥 |
| FGVC Aircraft | 0.341 | 0.290 | 0.283 | 0.362 💥 |
| Oxford Pets | 0.753 | 0.819 | 0.730 | 0.856 💥 |
| Caltech101 | 0.937 💥 | 0.914 | 0.922 | 0.932 |
| HatefulMemes | 0.585 💥 | 0.563 | 0.581 | 0.578 |
Полезные ссылки
Обратная связь
Круглосуточная поддержка по телефону 8 800 444-24-99, почте support@cloud.ru и в Telegram